
Hassan A. Karimi
MCNC, North Carolina Supercomputing
Center, P.O. Box 12889, 3021 Cornwallis Road, Research Triangle Park, NC
27709-2889, USA
karimi@mcnc.org
Dongming Hwang
IBM Corporation, Microelectronics
Division, Research Triangle Park, NC 27709, USA
dhwang@VNET.IBM.COM
KEYWORDS: routing,
parallel algorithms, GIS for transportation, parallel computing, real-time
routing
Routing problems are commonly solved using transportation networks and
functions provided by geographic information systems for transportation
(GIS-T) software. Certain transportation applications demand real-time
results - requiring real-time processing - while demanding best solutions
(that is, demanding best solutions in real time). An example of an emerging
real-time transportation application is risk assessment related to the
transport of hazardous materials using GIS-T (Freckmann
1993; List and Turnquist 1996; Patel and Horowitiz 1994). Over many
years researchers have tackled the problem of routing to achieve both best
solutions and fast performance. These efforts have resulted in two general
categories of routing algorithms. The first category contains algorithms
that guarantee optimal solutions but do not have good performance. The
best example of such an algorithm is the well known Dijkstra's
(1959) algorithm. The other category contains algorithms that although
very fast, they cannot guarantee best solutions; at best, they produce
good solutions. Most algorithms in this latter category are based on heuristic
approaches. Examples of heuristic algorithms that are used for routing
in transportation applications include A* (Nilsson
1980) and ORCA-H (Karimi 1996a).
A primary inhibitor to the
availability of routing algorithms that can produce best solutions in real
time is the use of serial algorithms that execute in scalar computing environments.
In order to implement routing algorithms that can guarantee optimal solutions
with fast performance, alternative computing environments and algorithms
need to be explored. We suggest that a parallel computing environment -
consisting of a parallel architecture (Treleaven
1988) and parallel algorithms - can overcome the above problem. A review
of the literature reveals that parallel processing approaches to compute
solutions to routing problems have been explored by others. An example
is the work on parallel processing for network analysis through decomposition
of shortest path algorithms for multiple instruction stream, multiple data
stream computers (Ding et al. 1992). Another
example is the work on developing parallel routing algorithms to be used
in the area of aerial path planning for search/surveillance operations
over terrain and for optimal route planning on terrain (Vezina
et
al. 1994). Also, Smith et al.
(1989) have discussed asynchronous, iterative, and parallel procedures
for solving the weighted-region least cost path problem. One major problem
with these parallel routing algorithms is that they are either mostly for
massively parallel processors that are categorized under supercomputers
or not designed for parallel computers.
Routing algorithms for supercomputers,
although are appropriate for certain transportation applications, are inconceivable
for use by many GIS-T users as supercomputers are expensive and are not
supported in current GIS-T. In other words, only a few GIS-T users have
access to supercomputers for special projects and applications. One other
drawback with supercomputers is that they are complex to use and users
require special skills for using them. Therefore, on the one hand, there
is a need to parallel computing environments to solve complex spatial problems,
and on the other hand, these environments must be easy to use and cost
effective and must be easily have accessed by GIS-T users.
An alternative approach,
which compared to supercomputers is less complex to use and is affordable
to GIS-T users, is the utilization of clusters of workstations or PCs;
that is, a network of workstations or PCs with each workstation or PC being
considered as one processor like in a parallel supercomputer. Although
the programming with this environment is still complex and the performance
may not be as fast as supercomputers, their costs are much less than supercomputers.
To gain a better understanding of clusters and their use for parallel processing,
a cluster of workstations is used in this paper to analyze the time complexity
of a parallel routing algorithm and its comparison with conventional serial
algorithms.
A new approach to solve
computationally intensive problems in GISs has been suggested by Karimi
(1996b).
This is a new paradigm in computing GIS, called "Open Computing GIS", where
all possible computing resources (desktops, workstations, and supercomputers)
are linked and used for computing spatial problems. With open computing
GIS, GIS desktop access to high-performance computing and communication
resources is made possible. For further details on this paradigm refer
to Karimi (1996b; 1996c).
For now, clusters, workstations
or PCs, are the most cost-effective parallel computing environments and
are available to the GIS community. Discussed in the following sections
are a parallel routing algorithm, its implementation on a cluster of workstations,
and an analysis of its performance.
2. A Parallel Routing Algorithm
Karimi and Hwang (1997) developed a parallel
algorithm which can be applied to any network, being a transportation network,
a very large-scale integration network, a hydrology network, or other networks.
The thrust of their work was to design and develop a general parallel algorithm
and its possible implementation on any parallel machine. The focus of this
work is primarily on describing a parallel routing algorithm for real-time
GIS-T applications and its implementation on a cluster of workstations.
The parallel algorithm used
in this work is based on domain decomposition and Dijkstra's algorithm.
Taking this approach, the network is first decomposed into equal size subnetworks.
The number of subnetworks is equal to the number of processors, called
processor elements (PEs), available in the underlying parallel computer
environment. Each subnetwork is connected to an adjacent subnetwork through
common nodes, called boundary nodes. These boundary nodes constitute a
network, called a hypernetwork, that contains the best routes and is much
smaller than the original subnetworks. The purpose of obtaining subnetworks
and the hypernetwork is that each subnetwork can be executed on one separate
PE in parallel and the results can be used in the hypernetwork to compute
the optimal route.
In each subnetwork, except
the subnetworks containing the origin and destination nodes, the best routes
between each pair of boundary nodes are computed. In the subnetworks with
the origin and destination nodes the best routes are computed, between
the origin node and the boundary nodes of the subnetwork containing the
origin node, and between the destination node and the boundary nodes of
the subnetwork containing the destination node. After these computations,
the hypernetwork, which contains the best route, is executed on one single
PE. For computation of best routes, or its pieces on subnetworks and the
hypernetwork, Dijkstra's algorithm is used. Decomposition of the network
is an important part of this parallel algorithm. Examples of different
strategies for decomposing networks include the work by Gilbert
and Zmijewski (1987), and the work by Frederickson
(1991).
The steps of this parallel
routing algorithm are as follows:
1. Decompose the network into subnetworks.
2. Identify the origin and destination vertices and the subnetworks
in which they are located.
3. Run Dijkstra's algorithm to compute shortest routes between the
origin and all boundary vertices within the subnetwork containing the origin.
4. Run Dijkstra's algorithm to compute shortest routes between the
destination and all boundary vertices within the subnetwork containing
the destination.
5. Within each of the remaining subnetworks, run Dijkstra's algorithm
to compute shortest routes between all pairs of boundary vertices.
6. Construct a hypernetwork representing all of the above computed
shortest routes between the various vertices; this entails creating a new
database of all of the vertices and links in the hypernetwork, as derived
in steps 3, 4, and 5.
7. Run Dijkstra's algorithm on the hypernetwork to compute the actual
shortest route between the network's origin and destination vertices.
This parallel algorithm can be implemented on any parallel architecture,
supercomputers or others. But for the reasons discussed above, the implementation
of this parallel algorithm on a cluster of workstations is discussed here.
A cluster of workstations was used to implement the parallel algorithm.
Each workstation in this cluster is a DEC Alpha 3000 machine with 175 MHz
Alpha 21064 processor, 96 MB physical memory, 3 GB local disk, running
OSF/1 operating system version 2.1. The network architecture is a DEC FDDI
GigaSwitch with 64-way non-blocking crossbar network switch which can have
up to 32 simultaneously active FDDI sessions, thus allowing 90% achievable
bandwidth on data transfers. The programming environment is a parallel
virtual machine (PVM) (Geist et al. 1994).
All PVM message passing takes place via the FDDI network.
The parallel algorithm was implemented using data sets with different numbers
of nodes and links and was executed using different numbers of PEs. In
Table
1 the timing of the parallel algorithm sizes of networks for different
number of PEs is shown. For comparison, the entire network was also implemented,
using Dijkstra's algorithm, on one of these workstations, that is serial
execution. In Figure 1, these results are compared
with the serial implementation of the algorithm.
Table 1 Execution times of the serial algorithm and the parallel algorithm
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
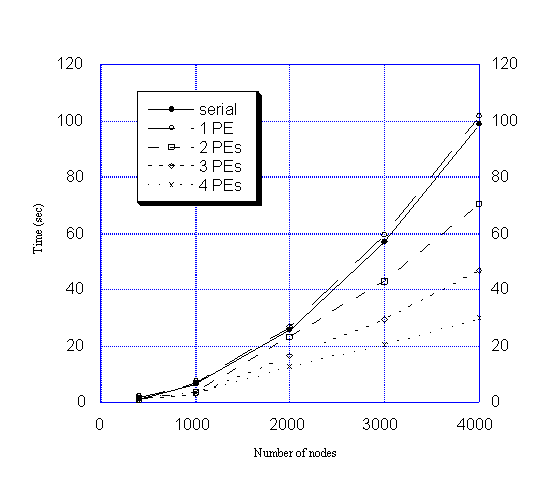
It is clear from Table
1 and Figure 1 that:
a) As the number of PEs increases the processing time improves.
b) For a small number of nodes, the parallel algorithm does not perform
better than the serial algorithm because the gain by parallel computing
is not sufficient to compensate for the overhead of message passing among
PEs.
c) For large number of nodes, the parallel algorithm performs obviously
better than the serial algorithm. Because each PE performs Dijkstra's algorithm
on a network with a smaller number of nodes, the complexity of Dijkstra's
algorithm reduces quadratically.
d) The difference in performance between the serial algorithm and the
parallel algorithm on one PE is due to the overhead involved in the PVM
programming environment.
An important concept in
measuring performance in parallel computing is speedup (S):
S = TS
/ TP
where, TS is
the serial execution time of the fastest known serial algorithm, and
TP
is the parallel execution of the chosen algorithm.
Table
2 shows the speedup for different number of PEs used and the percentage
of improvements. Again, due to the overhead involved in PVM programming,
from the speedup of the parallel algorithm on one PE it is clear that there
is no gain by parallel processing. A comparison between these speedups
is also shown in Figure 2. Clearly, the gain by
parallel processing is achieved when large sizes of networks are used.
Also, the use of larger number of PEs for the same size of networks improves
the speedup by order of magnitudes.
Table 2 Speedup of the parallel algorithm for different number of PEs and different sizes of networks
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
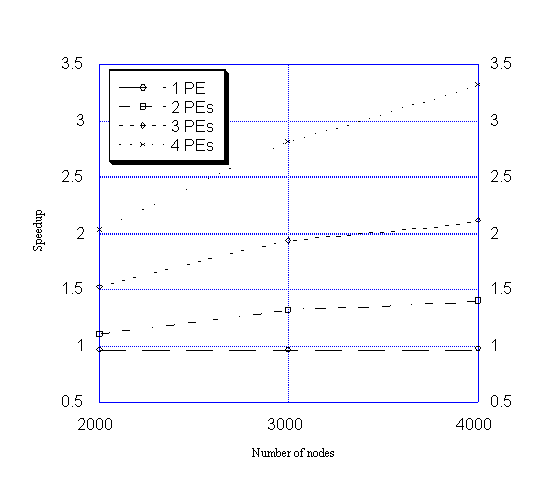
Figure 2 Speedups
of the parallel algorithm for different sizes of networks.
It is clear from Table
2 and Figure 2 that the speedup of the parallel
algorithm increases as either the number of PEs or the number of nodes
increases. This suggests that for large sizes of networks parallel processing
with a large number of PEs is advantageous. With these results, it is obvious
that parallel computing overcomes the time complexity barrier in GIS-T
for real time transportation applications.
The above performance of
the parallel algorithm was based on the worst case of Dijkstra's algorithm
(O(n2). The speedup of the
parallel algorithm can further be improved when priority queues for maintaining
the temporarily labeled nodes in Dijkstra's algorithm, having a O(n*log(n)).
complexity (Ahuja et al. 1993; Gallo and Pallottino
1988), are considered. The main objective for testing the parallel
routing algorithm was to analyze the results for the worst case, which
is (O(n2), on a cluster of
workstations. When the parallel algorithm shows a speedup of 2 to 3. 32
times for the worst case, its speedup for other cases (e.g., when priority
queues are used) would obviously be better. In other words, by demonstrating
that the parallel algorithm is able to improve the performance of Dijkstra's
algorithm in the worst case, it can be guaranteed that it would definitely
improve the performance of routing in all other possible cases. Furthermore,
Dijkstra's algorithm in many existing GIS-T software packages and applications
is based on the worst case (O(n2)),
which makes the contribution of this paper useful from a practical point
of view.
For achieving best routes in real time, alternative computing environments are to be considered. Parallel computing environments potentially produce best routes in real time. However, the use of parallel computers (supercomputers) is not acceptable to the GIS-T community as they are expensive and complex to use. To overcome this problem and to allow GIS-T users to benefit from parallel processing, the utilization of clusters of workstations or PCs is suggested. Such computing environments are easier to use and affordable and need to be explored for building new GIS - parallel GIS. The emergence of parallel GIS will overcome the time complexity of routing and many other spatial problems in GISs.
Ahuja, R. K., Magnanti, T. L., and Orlin, J. B. (1993) Network Flows: Theory, Algorithm and Applications. Englewood Cliffs, NJ: Prentice Hall.
Freckmann, P. (1993) Route Calculation for Dangerous Goods Transport with a Graphical Information System. Proceedings of the Fourth European Conference and Exhibition on Geographical Information Systems, EGIS Foundation, pp. 1132-1138. Utrecht.
Frederickson, G.N. (1991) Planar Graph Decomposition and All Pairs Shortest Paths, Journal of the Association of Computing Machinery, 38(1), 162-204.
Dijkstra, E.W. (1959) A Note on Two Problems in Connexion With Graphs. Numerische Mathematik, 1, 269-271.
Ding, Y., Densham, P.J., and Armstrong, M.P. (1992) Parallel Processing for Network Analysis: Decomposing Shortest Path Algorithms for MIMD Computers. Proceedings of the 5th International Symposium on Data Handling, pp. 682-691. Charleston, SC.
Gallo, G. and Pallottino, S. (1988) Shortest Paths Algorithms, Annals of Operation Research, 13, 3-79.
Geist, A., Beguelin, A., Dongarra, J., Jiang, W., Manchek, R., and Sunderam, V. (1994) PVM: Parallel Virtual Machine - A Users' Guide and Tutorial for Networked Parallel Computing, Cambridge, MA.: The MIT Press.
Gilbert, J.R., and Zmijewski, E. (1987) A Parallel Graph Partitioning Algorithm for a Message-Passing Multiprocessor. International Journal of Parallel Programming, 16, 427-449.
Karimi, H.A. (1996a) Real-Time Optimal-Route Computation: A Heuristic Approach. ITS Journal, 3(2), 111-127.
Karimi, H.A. (1996b) Open Computing GIS: An Effective, Affordable Approach to Solving Spatial Problems. GIS World, 9(3), 48-51.
Karimi, H.A. (1996c) A Flexible Computing Environment for Solving Spatial Problems. URISA Journal, 8(2), 51-62.
Karimi, H.A. and Hwang, D. (1997) A Parallel Algorithm for Routing: Best Solutions at Low Computational Costs. Geomatica, 51(1), 45-51.
List, G.F. and Turnquist, M.A. (1997) Routing and Emergency Response Team Siting for High-Level Radioactive Waste Shipments. IEEE Transactions on Engineering Management. Forthcoming.
Nilsson, N.J. (1980) Principles of Artificial Intelligence. Palo Alto, CA.: Tioga Publishing Co.
Patel, M.H. and Horowitz, A.J. (1994) Optimal Routing of Hazardous Materials Considering Risk of Spill. Transportation Research A, 28, 119-132.
Smith, T.R., Peng, G., and Gahinet, P. (1989) Asynchronous, Iterative, and Parallel Procedures for Solving the Weighted-Region Least Cost Path Problem. Geographical Analysis, 21, 147-166.
Treleaven, P. C. (1988) Parallel Architecture Overview. Parallel Computing, 8, 59-70.
Vezina, G., Ratzer, G., and Van Dongen, V. (1994) Parallel Spatial
Analysis and Interactive Visualization Software. Proceedings of the Canadian
Conference on GIS, June 6-10 1994, pp. 1048-1055. Ottawa.